Wade Brainerd



Put down that std::map!
This article is relatively negative in tone, a fact which I must apologize for in advance, and promise to try to rectify in further attempts at blogging.
Among efficiency-oriented programmers, there is social pressure to avoid programming techniques which are obtuse or costly, though they might offer some perceived safety or personal productivity cash-in.
But people get weak, and occasionally those who are typically hardcore will allow themselves to be led down dark paths.
As we all know, one such path is the C++ standard library of templated container classes, or STL.
Temptation
For C/C++ programmers, STL fills the same niche as those popular do-it-yourself website builders for artists and photographers.
All the data structures you are supposed to be building, and the algorithms you are supposed to be writing, are abstracted into cute boxes, and you feel really productive until something needs to work a little differently.
Thankfully, most people won’t jump to STL just for arrays. It’s a contiguous memory block, and people tend to be comfortable with compile time or explicit dynamic allocation.
The same is generally true of linked lists. Experienced programmers know all about the cache nightmare of splitting nodes and data records into individual allocations.
Most people are with me up to here. When we evaluate interns, we can separate the wheat from the chaff based on whether the stock raytracer assignment returns intersections in a std::vector.
But where people seem to give up is key value indexing. Tell someone to make a collection of data elements indexed by a string, and they immediately #include <map>.
Another way
I’m here to remind you about the hash table.
- It’s an array of ints.
- You can see the contents in the watch window without a personal assistant.
- Runs fine in Debug builds.
- Doesn’t bring the Microsoft CRT allocator to its knees.
- Insert and lookup functions are tiny and straightforward.
Here’s an simple example.
#define DATA_HASH_SIZE 16384
short dataHash[DATA_HASH_SIZE];We’ll just pretend there’s an array of data objects we can index using a short. short could be a pointer or even the value itself, if small.
This hash table is set to 16K elements max; this should be around twice the maximum number of data elements to avoid collision performance issues.
short LookupDataByName(const char* key)
{
uint slot = fnv_32_str(key, 0) % DATA_HASH_SIZE;
for (;;)
{
short dataIndex = dataHash[slot];
if (dataIndex < 0 || // not found
strcmp(data[dataIndex].key, key) == 0) // exact match
return dataIndex;
slot = (slot + 1) % DATA_HASH_SIZE;
}
}To search, we use a standard hash function to convert the key to a hash table index, and test to see if that index represents an exact match. If it does, or if it’s NULL, then the search is finished. Otherwise, we advance through the hash table until we find what we’re looking for or encounter NULL.
I’m illustrating an open addressing hash table, where collisions are dealt with by simply moving to the next hash table slot. If there is a collision or if the chosen slot is needed later, keys are simply pushed into later slots.
This works well until the hash table starts to get full, where long sequences of colliding entries make search time effectively linear.
Note that if the hash table were not sized at least as large as the data array, a check for returning to the first slot would be needed to avoid an infinite loop.
So, those are two reasons to make sure the hash table is large enough.
void InsertDataByName(const char* key, short dataIndex)
{
uint slot = fnv_32_str(key, 0) % DATA_HASH_SIZE;
for (;;)
{
if (dataHash[slot] < 0)
{
dataHash[slot] = dataIndex;
return;
}
slot = (slot + 1) % DATA_HASH_SIZE;
}
}The insert function is similar in structure to the lookup function, with the same caveat about the infinite loop check.
What’s the point?
For an array of shorts and two trivial functions you can keep the STL scourge at bay, and at the same time be happer with how your code runs.
Also, you can load this hash table from a data file, untouched. Which makes it a pretty good way to say, index the assets in a data file.
You’d probably like proof though, so I’ve posted a simple hash table benchmark on GitHub with data in a Google Sheet.
The contenders are the open addressing hash table, std::map, and the TR1 std::unordered_map.
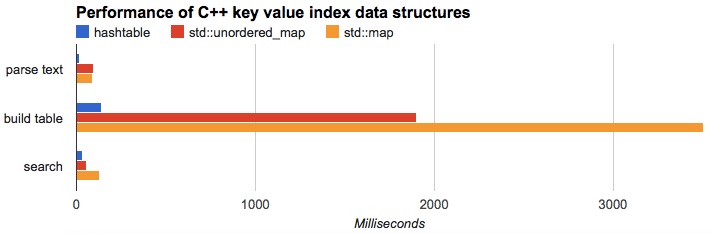
The unordered map (which may be a hash table internally) is certainly better than the ordinary map, but nowhere near C-style hash table performance.
Catch
Most readers will notice I didn’t provide a remove function.
In many data processing pipelines you’ll just build, use & dump the whole table, so you don’t need one.
If rapid insert and delete are important, you might choose to forego the open addressing scheme I selected in favor of something more malleable.
But that’s the whole point of choosing the algorithm that fits your needs.
Keep coding
Someone is now saying “I’ll refactor this into a template and keep it in my library.” Please don’t do that.
You will be better served by taking the time to attack the next problem carefully. By analyzing the requirements of the task and the characteristics of the data, intersecting with your knowledge of algorithms and data structures, and writing the best solution you can, from scratch.
There’s a tendency to want to box up things that we’ve written and keep them forever in a museum. “If I can just get this bitarray class to be perfect, nobody will ever have to think about bits again!”
But that’s just not what we’re meant to do; we’re paid to think about and write code. And coding should not descend into gluing together prefab pieces like highly paid kindergarteners.
Wade